Query Pipeline#
Concept#
LlamaIndex provides a declarative query API that allows you to chain together different modules in order to orchestrate simple-to-advanced workflows over your data.
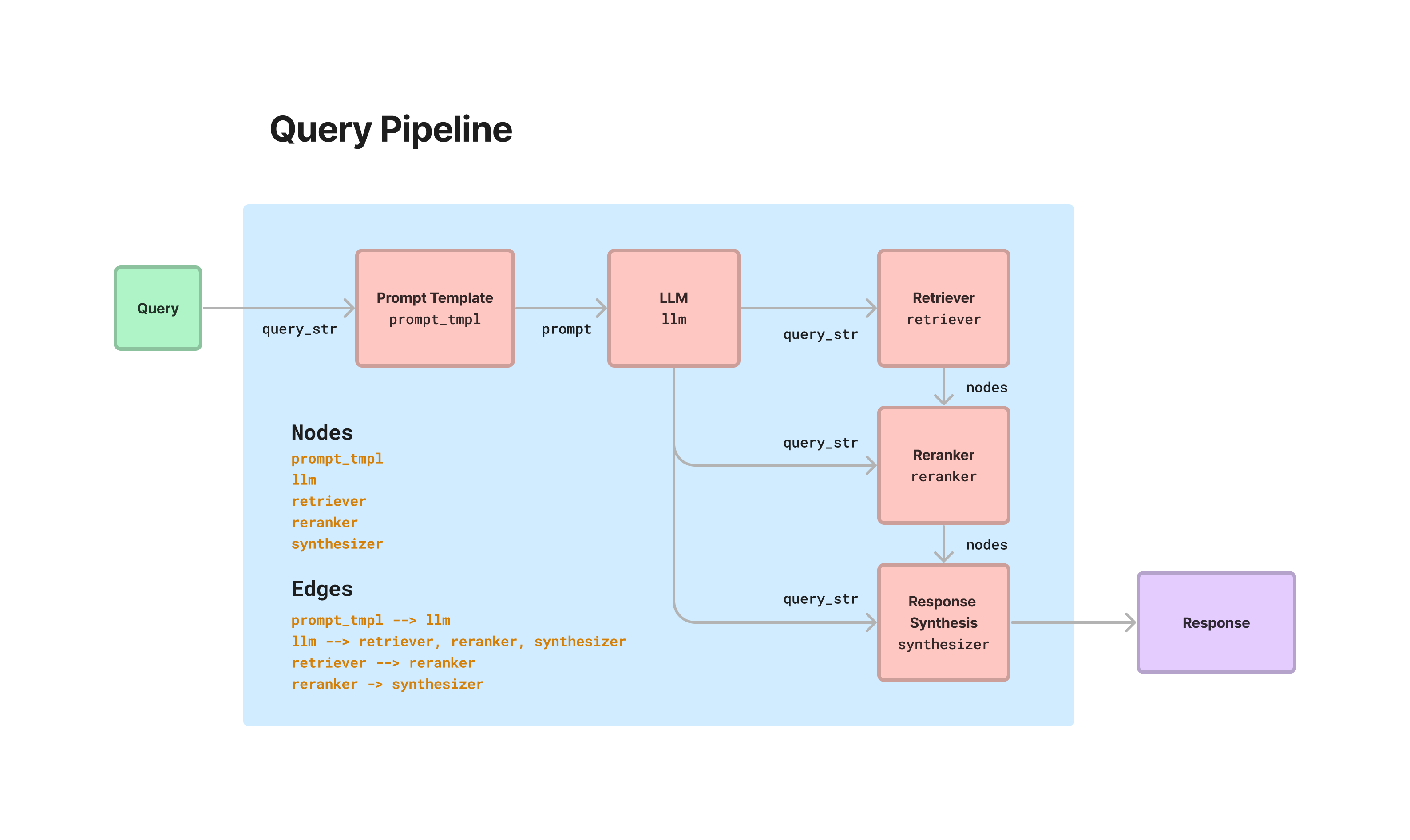
This is centered around our QueryPipeline abstraction. Load in a variety of modules (from LLMs to prompts to retrievers to other pipelines), connect them all together into a sequential chain or DAG, and run it end2end.
NOTE: You can orchestrate all these workflows without the declarative pipeline abstraction (by using the modules imperatively and writing your own functions). So what are the advantages of QueryPipeline?
Express common workflows with fewer lines of code/boilerplate
Greater readability
Greater parity / better integration points with common low-code / no-code solutions (e.g. LangFlow)
[In the future] A declarative interface allows easy serializability of pipeline components, providing portability of pipelines/easier deployment to different systems.
Our query pipelines also propagate callbacks throughout all sub-modules, and these integrate with our observability partners.
To see an interactive example of QueryPipeline being put in use, check out the RAG CLI.
Usage Pattern#
Here are two simple ways to setup a query pipeline - through a simplified syntax of setting up a sequential chain to setting up a full compute DAG.
from llama_index.query_pipeline.query import QueryPipeline
# sequential chain
p = QueryPipeline(chain=[prompt_tmpl, llm], verbose=True)
# DAG
p = QueryPipeline(verbose=True)
p.add_modules({"prompt_tmpl": prompt_tmpl, "llm": llm})
p.add_link("prompt_tmpl", "llm")
# run pipeline
p.run(prompt_key1="<input1>", ...)
More information can be found in our usage pattern guides below.
Module Guides#
Check out our QueryPipeline end-to-end guides to learn standard to advanced ways to setup orchestration over your data.