![]()
Portkey#
Portkey is a full-stack LLMOps platform that productionizes your Gen AI app reliably and securely.
Key Features of Portkey’s Integration with Llamaindex:#

-
Automated Fallbacks & Retries: Ensure your application remains functional even if a primary service fails.
Load Balancing: Efficiently distribute incoming requests among multiple models.
Semantic Caching: Reduce costs and latency by intelligently caching results.
-
Logging: Keep track of all requests for monitoring and debugging.
Requests Tracing: Understand the journey of each request for optimization.
Custom Tags: Segment and categorize requests for better insights.
📝 Continuous Improvement with User Feedback:
Feedback Collection: Seamlessly gather feedback on any served request, be it on a generation or conversation level.
Weighted Feedback: Obtain nuanced information by attaching weights to user feedback values.
Feedback Metadata: Incorporate custom metadata with the feedback to provide context, allowing for richer insights and analyses.
-
Virtual Keys: Portkey transforms original provider keys into virtual keys, ensuring your primary credentials remain untouched.
Multiple Identifiers: Ability to add multiple keys for the same provider or the same key under different names for easy identification without compromising security.
To harness these features, let’s start with the setup:
If you’re opening this Notebook on colab, you will probably need to install LlamaIndex 🦙.
!pip install llama-index
# Installing Llamaindex & Portkey SDK
!pip install -U llama_index
!pip install -U portkey-ai
# Importing necessary libraries and modules
from llama_index.llms import Portkey, ChatMessage
import portkey as pk
You do not need to install any other SDKs or import them in your Llamaindex app.
Step 1️⃣: Get your Portkey API Key and your Virtual Keys for OpenAI, Anthropic, and more#
Portkey API Key: Log into Portkey here, then click on the profile icon on top left and “Copy API Key”.
import os
os.environ["PORTKEY_API_KEY"] = "PORTKEY_API_KEY"
Navigate to the “Virtual Keys” page on Portkey dashboard and hit the “Add Key” button located at the top right corner.
Choose your AI provider (OpenAI, Anthropic, Cohere, HuggingFace, etc.), assign a unique name to your key, and, if needed, jot down any relevant usage notes. Your virtual key is ready!
 3. Now copy and paste the keys below - you can use them anywhere within the Portkey ecosystem and keep your original key secure and untouched.
3. Now copy and paste the keys below - you can use them anywhere within the Portkey ecosystem and keep your original key secure and untouched.openai_virtual_key_a = ""
openai_virtual_key_b = ""
anthropic_virtual_key_a = ""
anthropic_virtual_key_b = ""
cohere_virtual_key_a = ""
cohere_virtual_key_b = ""
If you don’t want to use Portkey’s Virtual keys, you can also use your AI provider keys directly.
os.environ["OPENAI_API_KEY"] = ""
os.environ["ANTHROPIC_API_KEY"] = ""
Step 2️⃣: Configure Portkey Features#
To harness the full potential of Portkey’s integration with Llamaindex, you can configure various features as illustrated above. Here’s a guide to all Portkey features and the expected values:
Feature |
Config Key |
Value(Type) |
Required |
|---|---|---|---|
API Key |
|
|
✅ Required (can be set externally) |
Mode |
|
|
✅ Required |
Cache Type |
|
|
❔ Optional |
Force Cache Refresh |
|
|
❔ Optional |
Cache Age |
|
|
❔ Optional |
Trace ID |
|
|
❔ Optional |
Retries |
|
|
❔ Optional |
Metadata |
|
|
❔ Optional |
Base URL |
|
|
❔ Optional |
api_keyandmodeare required values.You can set your Portkey API key using the Portkey constructor or you can also set it as an environment variable.
There are 3 modes - Single, Fallback, Loadbalance.
Single - This is the standard mode. Use it if you do not want Fallback OR Loadbalance features.
Fallback - Set this mode if you want to enable the Fallback feature. Check out the guide here.
Loadbalance - Set this mode if you want to enable the Loadbalance feature. Check out the guide here.
Here’s an example of how to set up some of these features:
portkey_client = Portkey(
mode="single",
)
# Since we have defined the Portkey API Key with os.environ, we do not need to set api_key again here
Step 3️⃣: Constructing the LLM#
With the Portkey integration, constructing an LLM is simplified. Use the LLMOptions function for all providers, with the exact same keys you’re accustomed to in your OpenAI or Anthropic constructors. The only new key is weight, essential for the load balancing feature.
openai_llm = pk.LLMOptions(
provider="openai",
model="gpt-4",
virtual_key=openai_virtual_key_a,
)
The above code illustrates how to utilize the LLMOptions function to set up an LLM with the OpenAI provider and the GPT-4 model. This same function can be used for other providers as well, making the integration process streamlined and consistent across various providers.
Step 4️⃣: Activate the Portkey Client#
Once you’ve constructed the LLM using the LLMOptions function, the next step is to activate it with Portkey. This step is essential to ensure that all the Portkey features are available for your LLM.
portkey_client.add_llms(openai_llm)
And, that’s it! In just 4 steps, you have infused your Llamaindex app with sophisticated production capabilities.
🔧 Testing the Integration#
Let’s ensure that everything is set up correctly. Below, we create a simple chat scenario and pass it through our Portkey client to see the response.
messages = [
ChatMessage(role="system", content="You are a helpful assistant"),
ChatMessage(role="user", content="What can you do?"),
]
print("Testing Portkey Llamaindex integration:")
response = portkey_client.chat(messages)
print(response)
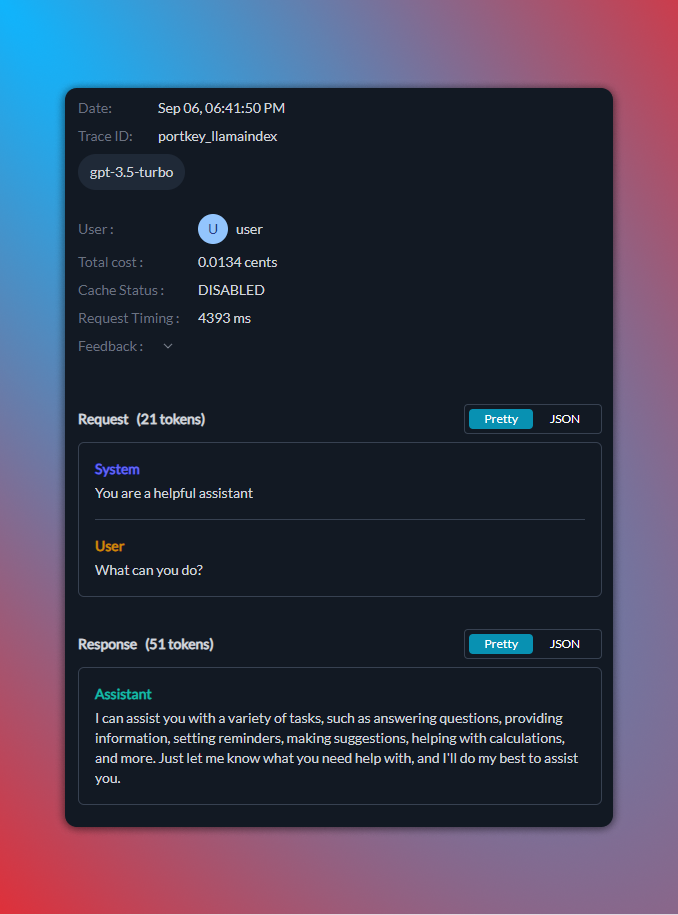
Here’s how your logs will appear on your Portkey dashboard:
⏩ Streaming Responses#
With Portkey, streaming responses has never been more straightforward. Portkey has 4 response functions:
.complete(prompt).stream_complete(prompt).chat(messages).stream_chat(messages)
While the complete function expects a string input(str), the chat function works with an array of ChatMessage objects.
Example usage:
# Let's set up a prompt and then use the stream_complete function to obtain a streamed response.
prompt = "Why is the sky blue?"
print("\nTesting Stream Complete:\n")
response = portkey_client.stream_complete(prompt)
for i in response:
print(i.delta, end="", flush=True)
# Let's prepare a set of chat messages and then utilize the stream_chat function to achieve a streamed chat response.
messages = [
ChatMessage(role="system", content="You are a helpful assistant"),
ChatMessage(role="user", content="What can you do?"),
]
print("\nTesting Stream Chat:\n")
response = portkey_client.stream_chat(messages)
for i in response:
print(i.delta, end="", flush=True)
🔍 Recap and References#
Congratulations! 🎉 You’ve successfully set up and tested the Portkey integration with Llamaindex. To recap the steps:
pip install portkey-ai
from llama_index.llms import Portkey
Grab your Portkey API Key and create your virtual provider keys from here.
Construct your Portkey client and set mode:
portkey_client=Portkey(mode="fallback")Construct your provider LLM with LLMOptions:
openai_llm = pk.LLMOptions(provider="openai", model="gpt-4", virtual_key=openai_key_a)Add the LLM to Portkey with
portkey_client.add_llms(openai_llm)Call the Portkey methods regularly like you would any other LLM, with
portkey_client.chat(messages)
Here’s the guide to all the functions and their params:
🔁 Implementing Fallbacks and Retries with Portkey#
Fallbacks and retries are essential for building resilient AI applications. With Portkey, implementing these features is straightforward:
Fallbacks: If a primary service or model fails, Portkey will automatically switch to a backup model.
Retries: If a request fails, Portkey can be configured to retry the request multiple times.
Below, we demonstrate how to set up fallbacks and retries using Portkey:
portkey_client = Portkey(mode="fallback")
messages = [
ChatMessage(role="system", content="You are a helpful assistant"),
ChatMessage(role="user", content="What can you do?"),
]
llm1 = pk.LLMOptions(
provider="openai",
model="gpt-4",
retry_settings={"on_status_codes": [429, 500], "attempts": 2},
virtual_key=openai_virtual_key_a,
)
llm2 = pk.LLMOptions(
provider="openai",
model="gpt-3.5-turbo",
virtual_key=openai_virtual_key_b,
)
portkey_client.add_llms(llm_params=[llm1, llm2])
print("Testing Fallback & Retry functionality:")
response = portkey_client.chat(messages)
print(response)
⚖️ Implementing Load Balancing with Portkey#
Load balancing ensures that incoming requests are efficiently distributed among multiple models. This not only enhances the performance but also provides redundancy in case one model fails.
With Portkey, implementing load balancing is simple. You need to:
Define the
weightparameter for each LLM. This weight determines how requests are distributed among the LLMs.Ensure that the sum of weights for all LLMs equals 1.
Here’s an example of setting up load balancing with Portkey:
portkey_client = Portkey(mode="ab_test")
messages = [
ChatMessage(role="system", content="You are a helpful assistant"),
ChatMessage(role="user", content="What can you do?"),
]
llm1 = pk.LLMOptions(
provider="openai",
model="gpt-4",
virtual_key=openai_virtual_key_a,
weight=0.2,
)
llm2 = pk.LLMOptions(
provider="openai",
model="gpt-3.5-turbo",
virtual_key=openai_virtual_key_a,
weight=0.8,
)
portkey_client.add_llms(llm_params=[llm1, llm2])
print("Testing Loadbalance functionality:")
response = portkey_client.chat(messages)
print(response)
🧠 Implementing Semantic Caching with Portkey#
Semantic caching is a smart caching mechanism that understands the context of a request. Instead of caching based solely on exact input matches, semantic caching identifies similar requests and serves cached results, reducing redundant requests and improving response times as well as saving money.
Let’s see how to implement semantic caching with Portkey:
import time
portkey_client = Portkey(mode="single")
openai_llm = pk.LLMOptions(
provider="openai",
model="gpt-3.5-turbo",
virtual_key=openai_virtual_key_a,
cache_status="semantic",
)
portkey_client.add_llms(openai_llm)
current_messages = [
ChatMessage(role="system", content="You are a helpful assistant"),
ChatMessage(role="user", content="What are the ingredients of a pizza?"),
]
print("Testing Portkey Semantic Cache:")
start = time.time()
response = portkey_client.chat(current_messages)
end = time.time() - start
print(response)
print(f"{'-'*50}\nServed in {end} seconds.\n{'-'*50}")
new_messages = [
ChatMessage(role="system", content="You are a helpful assistant"),
ChatMessage(role="user", content="Ingredients of pizza"),
]
print("Testing Portkey Semantic Cache:")
start = time.time()
response = portkey_client.chat(new_messages)
end = time.time() - start
print(response)
print(f"{'-'*50}\nServed in {end} seconds.\n{'-'*50}")
Portkey’s cache supports two more cache-critical functions - Force Refresh and Age.
cache_force_refresh: Force-send a request to your provider instead of serving it from a cache.
cache_age: Decide the interval at which the cache store for this particular string should get automatically refreshed. The cache age is set in seconds.
Here’s how you can use it:
# Setting the cache status as `semantic` and cache_age as 60s.
openai_llm = pk.LLMOptions(
provider="openai",
model="gpt-3.5-turbo",
virtual_key=openai_virtual_key_a,
cache_force_refresh=True,
cache_age=60,
)
🔬 Observability with Portkey#
Having insight into your application’s behavior is paramount. Portkey’s observability features allow you to monitor, debug, and optimize your AI applications with ease. You can track each request, understand its journey, and segment them based on custom tags. This level of detail can help in identifying bottlenecks, optimizing costs, and enhancing the overall user experience.
Here’s how to set up observability with Portkey:
metadata = {
"_environment": "production",
"_prompt": "test",
"_user": "user",
"_organisation": "acme",
}
trace_id = "llamaindex_portkey"
portkey_client = Portkey(mode="single")
openai_llm = pk.LLMOptions(
provider="openai",
model="gpt-3.5-turbo",
virtual_key=openai_virtual_key_a,
metadata=metadata,
trace_id=trace_id,
)
portkey_client.add_llms(openai_llm)
print("Testing Observability functionality:")
response = portkey_client.chat(messages)
print(response)
🌉 Open Source AI Gateway#
Portkey’s AI Gateway uses the open source project Rubeus internally. Rubeus powers features like interoperability of LLMs, load balancing, fallbacks, and acts as an intermediary, ensuring that your requests are processed optimally.
One of the advantages of using Portkey is its flexibility. You can easily customize its behavior, redirect requests to different providers, or even bypass logging to Portkey altogether.
Here’s an example of customizing the behavior with Portkey:
portkey_client.base_url=None
📝 Feedback with Portkey#
Continuous improvement is a cornerstone of AI. To ensure your models and applications evolve and serve users better, feedback is vital. Portkey’s Feedback API offers a straightforward way to gather weighted feedback from users, allowing you to refine and improve over time.
Here’s how to utilize the Feedback API with Portkey:
Read more about Feedback here.
import requests
import json
# Endpoint URL
url = "https://api.portkey.ai/v1/feedback"
# Headers
headers = {
"x-portkey-api-key": os.environ.get("PORTKEY_API_KEY"),
"Content-Type": "application/json",
}
# Data
data = {"trace_id": "llamaindex_portkey", "value": 1}
# Making the request
response = requests.post(url, headers=headers, data=json.dumps(data))
# Print the response
print(response.text)
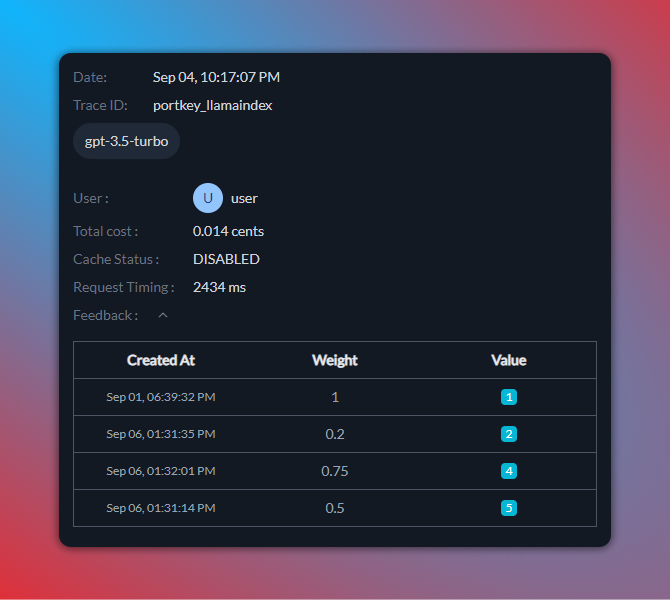
All the feedback with weight and value for each trace id is available on the Portkey dashboard:
✅ Conclusion#
Integrating Portkey with Llamaindex simplifies the process of building robust and resilient AI applications. With features like semantic caching, observability, load balancing, feedback, and fallbacks, you can ensure optimal performance and continuous improvement.
By following this guide, you’ve set up and tested the Portkey integration with Llamaindex. As you continue to build and deploy AI applications, remember to leverage the full potential of this integration!
For further assistance or questions, reach out to the developers ➡️

Join our community of practitioners putting LLMs into production ➡️
