Embeddings#
Concept#
Embeddings are used in LlamaIndex to represent your documents using a sophisticated numerical representation. Embedding models take text as input, and return a long list of numbers used to capture the semantics of the text. These embedding models have been trained to represent text this way, and help enable many applications, including search!
At a high level, if a user asks a question about dogs, then the embedding for that question will be highly similar to text that talks about dogs.
When calculating the similarity between embeddings, there are many methods to use (dot product, cosine similarity, etc.). By default, LlamaIndex uses cosine similarity when comparing embeddings.
There are many embedding models to pick from. By default, LlamaIndex uses text-embedding-ada-002 from OpenAI. We also support any embedding model offered by Langchain here, as well as providing an easy to extend base class for implementing your own embeddings.
Usage Pattern#
Most commonly in LlamaIndex, embedding models will be specified in the Settings object, and then used in a vector index. The embedding model will be used to embed the documents used during index construction, as well as embedding any queries you make using the query engine later on. You can also specify embedding models per-index.
If you don't already have your embeddings installed:
pip install llama-index-embeddings-openai
Then:
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core import VectorStoreIndex
from llama_index.core import Settings
# changing the global default
Settings.embed_model = OpenAIEmbedding()
# local usage
embedding = OpenAIEmbedding().get_text_embedding("hello world")
embeddings = OpenAIEmbedding().get_text_embeddings(
["hello world", "hello world"]
)
# per-index
index = VectorStoreIndex.from_documents(documents, embed_model=embed_model)
To save costs, you may want to use a local model.
pip install llama-index-embeddings-huggingface
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings
Settings.embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-en-v1.5"
)
This will use a well-performing and fast default from Hugging Face.
You can find more usage details and available customization options below.
Getting Started#
The most common usage for an embedding model will be setting it in the global Settings object, and then using it to construct an index and query. The input documents will be broken into nodes, and the embedding model will generate an embedding for each node.
By default, LlamaIndex will use text-embedding-ada-002, which is what the example below manually sets up for you.
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core import Settings
# global default
Settings.embed_model = OpenAIEmbedding()
documents = SimpleDirectoryReader("./data").load_data()
index = VectorStoreIndex.from_documents(documents)
Then, at query time, the embedding model will be used again to embed the query text.
query_engine = index.as_query_engine()
response = query_engine.query("query string")
Customization#
Batch Size#
By default, embeddings requests are sent to OpenAI in batches of 10. For some users, this may (rarely) incur a rate limit. For other users embedding many documents, this batch size may be too small.
# set the batch size to 42
embed_model = OpenAIEmbedding(embed_batch_size=42)
Local Embedding Models#
The easiest way to use a local model is by using HuggingFaceEmbedding from llama-index-embeddings-huggingface:
# pip install llama-index-embeddings-huggingface
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings
Settings.embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-en-v1.5"
)
Which loads the BAAI/bge-small-en-v1.5 embedding model. You can use any Sentence Transformers embedding model from Hugging Face.
Beyond the keyword arguments available in the HuggingFaceEmbedding constructor, additional keyword arguments are passed down to the underlying SentenceTransformer instance, like backend, model_kwargs, truncate_dim, revision, etc.
ONNX or OpenVINO optimizations#
LlamaIndex also supports using ONNX or OpenVINO to speed up local inference, by relying on Sentence Transformers and Optimum.
Some prerequisites:
pip install llama-index-embeddings-huggingface
# Plus any of the following:
pip install optimum[onnxruntime-gpu] # For ONNX on GPUs
pip install optimum[onnxruntime] # For ONNX on CPUs
pip install optimum-intel[openvino] # For OpenVINO
Creation with specifying the model and output path:
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings
Settings.embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-en-v1.5",
backend="onnx", # or "openvino"
)
If the model repository does not already contain an ONNX or OpenVINO model, then it will be automatically converted using Optimum. See the Sentence Transformers documentation for benchmarks of the various options.
What if I want to use an optimized or quantized model checkpoint instead?
It's common for embedding models to have multiple ONNX and/or OpenVINO checkpoints, for example sentence-transformers/all-mpnet-base-v2 with 2 OpenVINO checkpoints and 9 ONNX checkpoints. See the Sentence Transformers documentation for more details on each of these options and their expected performance. You can specify afile_name in the model_kwargs argument to load a specific checkpoint. For example, to load the openvino/openvino_model_qint8_quantized.xml checkpoint from the sentence-transformers/all-mpnet-base-v2 model repository:
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings
quantized_model = HuggingFaceEmbedding(
model_name="sentence-transformers/all-mpnet-base-v2",
backend="openvino",
device="cpu",
model_kwargs={"file_name": "openvino/openvino_model_qint8_quantized.xml"},
)
Settings.embed_model = quantized_model
What option should I use on CPUs?
As shown in the Sentence Transformers benchmarks, OpenVINO quantized to int8 (openvino_model_qint8_quantized.xml) is extremely performant, at a small cost to accuracy. If you want to ensure identical results, then the basic backend="openvino" or backend="onnx" might be the strongest options.
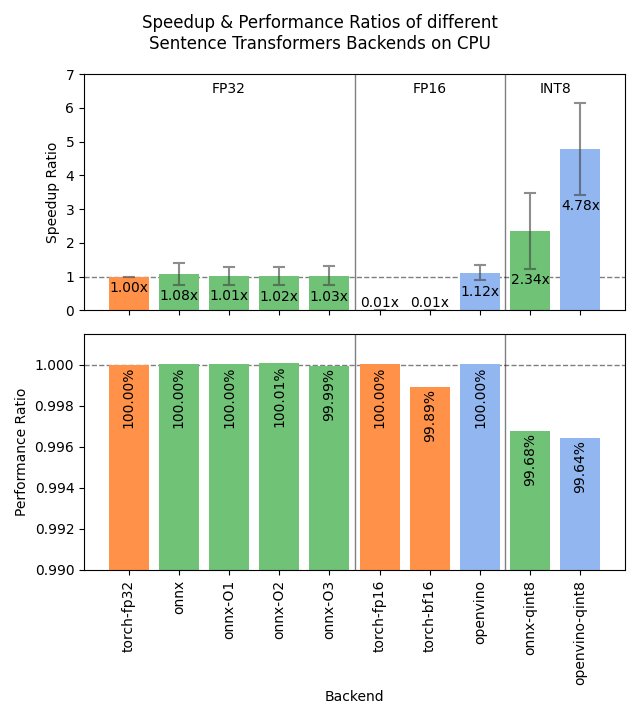 Given this query and these documents, the following results were obtained with int8 quantized OpenVINO versus the default Hugging Face model:
Given this query and these documents, the following results were obtained with int8 quantized OpenVINO versus the default Hugging Face model:
query = "Which planet is known as the Red Planet?"
documents = [
"Venus is often called Earth's twin because of its similar size and proximity.",
"Mars, known for its reddish appearance, is often referred to as the Red Planet.",
"Jupiter, the largest planet in our solar system, has a prominent red spot.",
"Saturn, famous for its rings, is sometimes mistaken for the Red Planet.",
]
HuggingFaceEmbedding(device='cpu'):
- Average throughput: 38.20 queries/sec (over 5 runs)
- Query-document similarities tensor([[0.7783, 0.4654, 0.6919, 0.7010]])
HuggingFaceEmbedding(backend='openvino', device='cpu', model_kwargs={'file_name': 'openvino_model_qint8_quantized.xml'}):
- Average throughput: 266.08 queries/sec (over 5 runs)
- Query-document similarities tensor([[0.7492, 0.4623, 0.6606, 0.6556]])
Click to see a reproduction script
import time
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings
quantized_model = HuggingFaceEmbedding(
model_name="sentence-transformers/all-mpnet-base-v2",
backend="openvino",
device="cpu",
model_kwargs={"file_name": "openvino/openvino_model_qint8_quantized.xml"},
)
quantized_model_desc = "HuggingFaceEmbedding(backend='openvino', device='cpu', model_kwargs={'file_name': 'openvino_model_qint8_quantized.xml'})"
baseline_model = HuggingFaceEmbedding(
model_name="sentence-transformers/all-mpnet-base-v2",
device="cpu",
)
baseline_model_desc = "HuggingFaceEmbedding(device='cpu')"
query = "Which planet is known as the Red Planet?"
def bench(model, query, description):
for _ in range(3):
model.get_agg_embedding_from_queries([query] * 32)
sentences_per_second = []
for _ in range(5):
queries = [query] * 512
start_time = time.time()
model.get_agg_embedding_from_queries(queries)
sentences_per_second.append(len(queries) / (time.time() - start_time))
print(
f"{description:<120}: Avg throughput: {sum(sentences_per_second) / len(sentences_per_second):.2f} queries/sec (over 5 runs)"
)
bench(baseline_model, query, baseline_model_desc)
bench(quantized_model, query, quantized_model_desc)
# Example documents for similarity comparison. The first is the correct one, and the rest are distractors.
docs = [
"Mars, known for its reddish appearance, is often referred to as the Red Planet.",
"Venus is often called Earth's twin because of its similar size and proximity.",
"Jupiter, the largest planet in our solar system, has a prominent red spot.",
"Saturn, famous for its rings, is sometimes mistaken for the Red Planet.",
]
baseline_query_embedding = baseline_model.get_query_embedding(query)
baseline_doc_embeddings = baseline_model.get_text_embedding_batch(docs)
quantized_query_embedding = quantized_model.get_query_embedding(query)
quantized_doc_embeddings = quantized_model.get_text_embedding_batch(docs)
baseline_similarity = baseline_model._model.similarity(
baseline_query_embedding, baseline_doc_embeddings
)
print(
f"{baseline_model_desc:<120}: Query-document similarities {baseline_similarity}"
)
quantized_similarity = quantized_model._model.similarity(
quantized_query_embedding, quantized_doc_embeddings
)
print(
f"{quantized_model_desc:<120}: Query-document similarities {quantized_similarity}"
)
What option should I use on GPUs?
On GPUs, OpenVINO is not particularly interesting, and ONNX does not necessarily outperform a quantized model running in the defaulttorch backend.
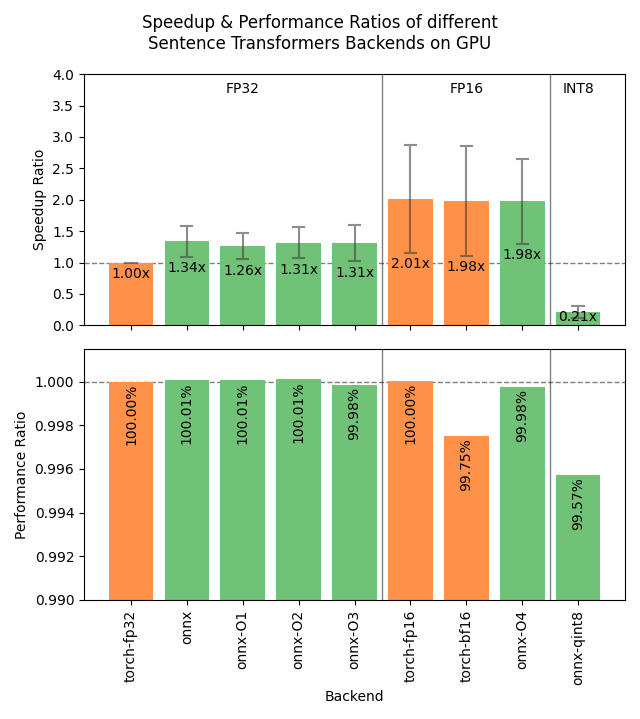 That means that you don't need additional dependencies for a strong speedup on GPUs, you can just use a lower precision when loading the model:
That means that you don't need additional dependencies for a strong speedup on GPUs, you can just use a lower precision when loading the model:
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings
Settings.embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-en-v1.5",
device="cuda",
model_kwargs={"torch_dtype": "float16"},
)
What if my desired model does not have my desired backend and optimization or quantization?
The backend-export Hugging Face Space can be used to convert any Sentence Transformers model to ONNX or OpenVINO with quantization or optimization applied. This will create a pull request to the model repository with the converted model files. You can then use this model in LlamaIndex by specifying therevision argument like so:
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings
Settings.embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-en-v1.5",
backend="openvino",
revision="refs/pr/16", # for pull request 16: https://huggingface.co/BAAI/bge-small-en-v1.5/discussions/16
model_kwargs={"file_name": "openvino_model_qint8_quantized.xml"},
)
LangChain Integrations#
We also support any embeddings offered by Langchain here.
The example below loads a model from Hugging Face, using Langchain's embedding class.
pip install llama-index-embeddings-langchain
from langchain.embeddings.huggingface import HuggingFaceBgeEmbeddings
from llama_index.core import Settings
Settings.embed_model = HuggingFaceBgeEmbeddings(model_name="BAAI/bge-base-en")
Custom Embedding Model#
If you wanted to use embeddings not offered by LlamaIndex or Langchain, you can also extend our base embeddings class and implement your own!
The example below uses Instructor Embeddings (install/setup details here), and implements a custom embeddings class. Instructor embeddings work by providing text, as well as "instructions" on the domain of the text to embed. This is helpful when embedding text from a very specific and specialized topic.
from typing import Any, List
from InstructorEmbedding import INSTRUCTOR
from llama_index.core.embeddings import BaseEmbedding
class InstructorEmbeddings(BaseEmbedding):
def __init__(
self,
instructor_model_name: str = "hkunlp/instructor-large",
instruction: str = "Represent the Computer Science documentation or question:",
**kwargs: Any,
) -> None:
super().__init__(**kwargs)
self._model = INSTRUCTOR(instructor_model_name)
self._instruction = instruction
def _get_query_embedding(self, query: str) -> List[float]:
embeddings = self._model.encode([[self._instruction, query]])
return embeddings[0]
def _get_text_embedding(self, text: str) -> List[float]:
embeddings = self._model.encode([[self._instruction, text]])
return embeddings[0]
def _get_text_embeddings(self, texts: List[str]) -> List[List[float]]:
embeddings = self._model.encode(
[[self._instruction, text] for text in texts]
)
return embeddings
async def _get_query_embedding(self, query: str) -> List[float]:
return self._get_query_embedding(query)
async def _get_text_embedding(self, text: str) -> List[float]:
return self._get_text_embedding(text)
Standalone Usage#
You can also use embeddings as a standalone module for your project, existing application, or general testing and exploration.
embeddings = embed_model.get_text_embedding(
"It is raining cats and dogs here!"
)
List of supported embeddings#
We support integrations with OpenAI, Azure, and anything LangChain offers.